Highlights
New Problem
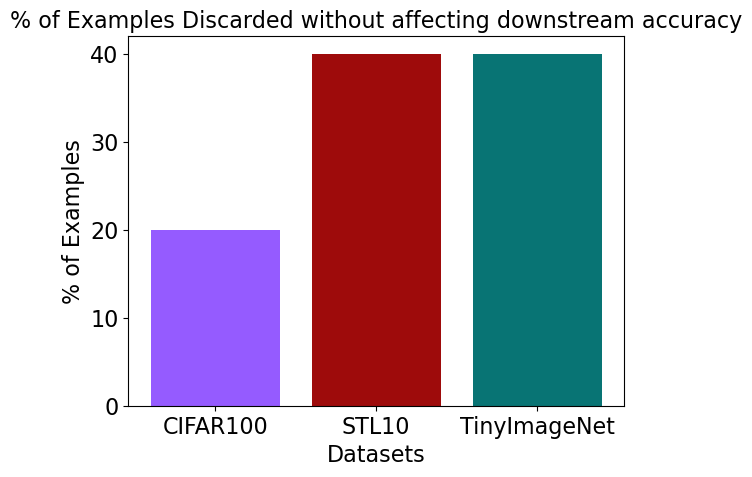
Previous work has studied data-efficiency for supervised learning and shown that nearly 30% of examples can be discarded on many datasets without sacrificing accuracy. However, this problem has not been studied for self-supervised learning. Our paper proposes the first empirical and theoretical method for data-efficient contrastive learning. We show that across various datasets (CIFAR100, STL10 and TinyImageNet), our method allows you to discard 20-40% of examples without affecting downstream classification accuracy.
Theoretical Guarantees for Downstream Accuracy
We use [Huang et al. 2023] theoretical characterization of contrastive learning using alignment and divergence of class centers to show that the subset we choose preserves alignment and divergence of class centers and thus preserves downstream accuracy.